Performance Tuning - Networking
Abstract
This article is one of the performance tuning serias. This one is intended to introduce networking tuning.
Table of Contents
- Abstract
- Table of Contents
- Architecture
- Considerations
- Monitoring and Diagnosing
- Generic Tuning
- Congestion control algorithms
- Parameters
- TCP Parameters to Consider
- fast socket recycle for socket in TIME-WAIT state
- enable TIME-WAIT socket used for new TCP connection
Architecture
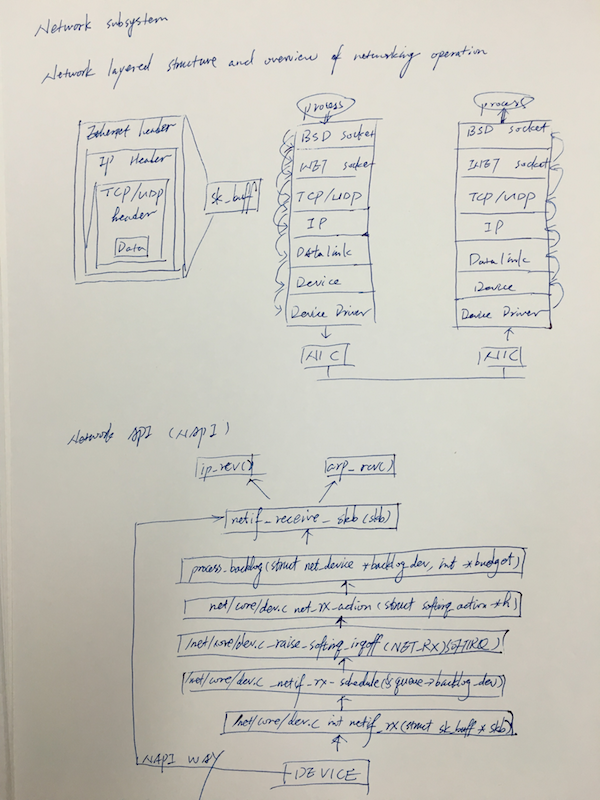
NAPI (Network API)
NAPI was introduced to counter the overhead associated with processing network traffic. For the first packet, NAPI works like the traditional implementation as it issues an interrupt for the first packet. After that, the interface goes into a polling mode. As long as there are packets in the DMA ring buffer of the network interface, no new interrupts will be caused, effectively reducing context switching and the associated overhead. Should the last packet be processed and the ring buffer be emptied, then the interface card will again fall back into the interrupt mode.
NAPI also has the advantage of improved multiprocessor scalibility by creating soft interrupts that can be processed by multiple processors.
Considerations
packet -> NIC -> internal hardware buffer or ring buffer
-> hardware interrupt request -> software interrupt operation
-> from buffer to network stack ->
* forwarded
* discarded
* rejected
* passed to a socket receive queue for an application ->
-----------------------------------------------
| remove from network stack |
| until no packets left in NIC buffer or |
| a certain number of packets are transferred |
| (/proc/sys/net/core/dev_weight) |
-----------------------------------------------
hardware malfunction or faulty infrastructure, verify hardware and infrastructure are working as expected
Bottolenecks in packet reception
- The NIC hardware buffer or ring buffer
- The hardware or software interrupt queues
- The socket receive queue for the application
Monitoring and Diagnosing
- ss
- ip
- ethtool
- /proc/net/snmp
- SystemTap
- nettop.stp
- socket-trace.stp
- dropwatch.stp
- latencytap.stp
Performance Metrics
- packets received and sent
- bytes received and sent
- collisions per second
- the number of collisions that occur on the network that the respective interface is connected to
- sustained values of collisions often concerns a bottleneck in the network infrastructure (consists of hubs ?) other than the server
- packets dropped
- either due to firewall configuration or due to a lack of network buffers
- overruns
- represents the number of times that the network interface ran out of buffer space
- this metric should be used in conjunction with the packets dropped value to identify a possible bottleneck in network buffers or the network queue length
- errors
- the number of frames marked as faulty
- this is often caused by a network mismatch or a partially broken network cable
Generic Tuning
Configure The Hardware Buffer (packet dropping)
show the input traffic
- filter incoming traffic
- reduce multicast groups
- reduce the amount of broadcast traffic
- resize the hardware buffer queue
- modify rx/tx parameters of the network drivers
- ethertool –set-ring devname value
- change the drain rate of the queue
- sysctl
- /proc/sys/net/core/dev_weight
- Notes
- device weight refers to the number of packets a driver can receive at one time, higher value will use additional processor time during which no other processs can be scheduled
Configure Interrupt Queues
packet receipt:
high-latency
interrupt-based -------------------> poll-based
Busy polling helps reduce latency in the network receive path by
- allowing socket layer code to poll the receive queue of a network device,
- and disable network interrupts.
This eliminates
- delays caused by the interrupts
- and the resultant context switches
However, it
- increses CPU utilization.
- Also prevent the CPU from sleeping, which can incur additional power comsumption.
Busy polling is disabled by default.
Set net.core.busy_poll to a value other than 0 to enable it.
This parameter controls the number of microseconds to wait for packets on the device queue for socket pool and selects. Red Hat recemmends a value of 50.
Add the SO_BUSY_POLL socket option to the socket.
Configure Socket Receive Queues
to increse the socket queue drain rate:
- Decrease the speed of incoming traffic
- filter
- dropping
- lower device weight
- Increse the depth of the application’s socket queue (not a long-term solution)
Configuration:
-
- /proc/sys/net/core/rmem_default
- This parameter controls the default size of the receive buffer used by sockets
-
- Use
setsockoptto configure a largerSO_RCVBUFvalue - This parameter controls the maximum size in bytes of a socket’s receive buffer. Use
getsockoptto get current value.man 7 socket
- Use
Configure Receive-Side Scaling (RSS)
RSS also known as multi-queue receive.
Configure Receive Packet Steering (RPS)
- used to direct packets to specific CPUs for processing
- implemented at the software level
-
helps to prevent the hardware queue of a single NIC from becoming a bottleneck in network traffic
- can be used with any NIC
- easy to add software filters to RPS to deal with new protocols
- does not increse the hardware interrupt rate of the network device
- however, it does introduce inter-processor interrupts
/sys/class/net/device/queues/rx-queue/rps_cpus
value: 0 disable RPS, so that the CPU that handles the network interrupt also process the packet
[root@dns will]# cat /sys/class/net/eno0/queues/rx-0/rps_cpus
00000000,00000000,00000000,00000000
Configure Receive Flow Steering (RFS)
RFS extends RPS behavior to increse the CPU cache hit rate and thereby reduce network latency.
RPS forwards packet based solely on queue length.
RFS use RPS backend to calculate the most appropriate CPU, then forwards packet based on the location of the application consuming the packets, this increse CPU cache efficiency.
RFS is disabled by default.
- /proc/sys/net/core/rps_socket_flow_entriens
- /sys/class/net/device/queues/rx-queue/rps_flow_cnt
Configure Accelerated RFS
prerequiste
- must be supported by the NIC
- tuple filtering must be enabled
Congestion control algorithms
- cubic
- reno
Parameters
All TCP/IP tunning parameters are located under /proc/sys/net/. Keep in mind everything under /proc is volatile, so any changes you make are lost after reboot.
/proc/sys/net/core/rmem_max - Maximum TCP Receive Window
/proc/sys/net/core/wmem_max - Maximum TCP Send Window
/proc/sys/net/ipv4/tcp_rmem - memory reserved for TCP rcv buffers (reserved memory per connection default)
/proc/sys/net/ipv4/tcp_wmem - memory reserved for TCP snd buffers (reserved memory per connection default)
/proc/sys/net/ipv4/tcp_timestamps - Timestamps (RFC 1323) add 12 bytes to the TCP header...
/proc/sys/net/ipv4/tcp_sack - TCP Selective Acknowledgements. They can reduce retransmissions, however make servers more prone to DDoS Attacks and increase CPU utilization.
/proc/sys/net/ipv4/tcp_window_scaling - support for large TCP Windows (RFC 1323). Needs to be set to 1 if the Max TCP Window is over 65535.
- tcp_timestamps
- add additional 10 bytes to each packet
- but more accurate timestamp make TCP congestion control algorithms work better
- and are recommonded for fast networks
The tcp_rmem and tcp_wmem contain arrays of three parameter values: the 3 numbers represent minimum, default and maximum memory values. Those 3 values are used to bound autotunning and balance memory usage while under global memory stress.
# Default Socket Receive Buffer
net.core.rmem_default = 31457280
# Maximum Socket Receive Buffer
net.core.rmem_max = 12582912
# Default Socket Send Buffer
net.core.wmem_default = 31457280
# Maximum Socket Send Buffer
net.core.wmem_max = 12582912
# Increase number of incoming connections
net.core.somaxconn = 4096
# Increase number of incoming connections backlog
net.core.netdev_max_backlog = 65536
# Increase the maximum amount of option memory buffers
net.core.optmem_max = 25165824
# Increase the maximum total buffer-space allocatable
# This is measured in units of pages (4096 bytes)
net.ipv4.tcp_mem = 65536 131072 262144
net.ipv4.udp_mem = 65536 131072 262144
# Increase the read-buffer space allocatable
net.ipv4.tcp_rmem = 8192 87380 16777216
net.ipv4.udp_rmem_min = 16384
# Increase the write-buffer-space allocatable
net.ipv4.tcp_wmem = 8192 65536 16777216
net.ipv4.udp_wmem_min = 16384
# Increase the tcp-time-wait buckets pool size to prevent simple DOS attacks
net.ipv4.tcp_max_tw_buckets = 1440000
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
Note: To manually set the MTU value under Linux, use the command: ifconfig eth0 mtu 1500 (where 1500 is the desired MTU size)
TCP Parameters to Consider
- TCP_FIN_TIMEOUT
- This setting determines the time that must elapse before TCP/IP can release a closed connection and reuse its resources. During this TIME_WAIT state, reopening the connection to the client costs less than establishing a new connection. By reducing the value of this entry, TCP/IP can release closed connections faster, making more resources available for new connections. Adjust this in the presence of many connections sitting in the TIME_WAIT state:
net.ipv4.tcp_fin_timeout = 15 (default: 60 seconds, recommended 15-30 seconds)
- TCP_KEEPALIVE_INTERVAL
- This determines the wait time between isAlive interval probes.
net.ipv4.tcp_keepalive_intvl = 30
(default: 75 seconds, recommended: 15-30 seconds)
TCP_KEEPALIVE_PROBES This determines the number of probes before timing out.
net.ipv4.tcp_keepalive_probes = 5
(default: 9, recommended 5)
- TCP_TW_RECYCLE
- It enables fast recycling of TIME_WAIT sockets. The default value is 0 (disabled). The sysctl documentation incorrectly states the default as enabled. It can be changed to 1 (enabled) in many cases. Known to cause some issues with hoststated (load balancing and fail over) if enabled, should be used with caution.
fast socket recycle for socket in TIME-WAIT state
net.ipv4.tcp_tw_recycle=1 (0 by default)
(boolean, default: 0)
- TCP_TW_REUSE
- This allows reusing sockets in TIME_WAIT state for new connections when it is safe from protocol viewpoint. Default value is 0 (disabled). It is generally a safer alternative to tcp_tw_recycle
sysctl.conf syntax: net.ipv4.tcp_tw_reuse=1 (0 by default)
enable TIME-WAIT socket used for new TCP connection
(boolean, default: 0)
Note: The tcp_tw_reuse setting is particularly useful in environments where numerous short connections are open and left in TIME_WAIT state, such as web servers. Reusing the sockets can be very effective in reducing server load.
Netfilter
Linux has an advanced firewall capability as a part of the kernel.
Netfilter provides functions:
- packet filtering
- address translation
- if a packet matches a rule, Netfilter alter the packet to meet the address translation requirements
Properties that matching filter can be defined with:
- Network interface
- IP address, IP address range, subnet
- Protocol
- ICMP type
- Port
- TCP flag
- State
Work Flow
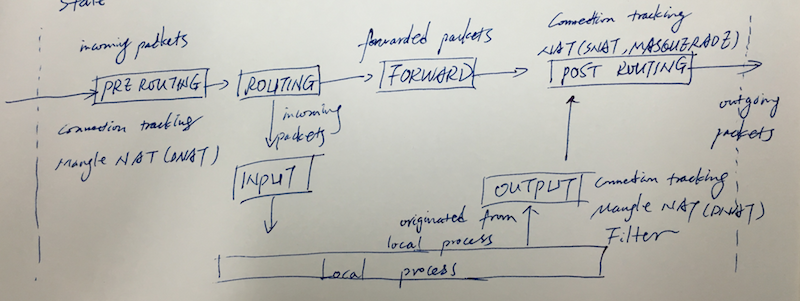
Possible Target
- ACCEPT
- DROP
- REJECT
- discard the packet by sending back the packet such as ICMP port unreachable, TCP reset to the originating host
- LOG
- Address translation
- MASQUERADE
- SNAT
- DNAT
- REDIRECT
States
Netfilter classifies each packet into one of the following 4 states:
- NEW
- ESTABLISHED
- RELATED
- INVALID
- malformed or invalid packet
Configure
sysctl netfilter
To reduce the number of connections in TIME_WAIT state, we can decrease the number of seconds connections are kept in this state before being dropped:
# reduce TIME_WAIT from the 120s default to 30-60s
net.netfilter.nf_conntrack_tcp_timeout_time_wait=30
# reduce FIN_WAIT from teh 120s default to 30-60s
net.netfilter.nf_conntrack_tcp_timeout_fin_wait=30
Misc Notes: You may want to reduce net.netfilter.nf_conntrack_tcp_timeout_established to 900 or some manageable number as well.
Traffic Control
TCP/IP transfer window
high-speed networks can use a technique called window scaling to increse the maximum transfer window size even more.
Offload
if the network adapter supports hardware offloads functionality, the kernel can offload part of its task to the adapter and it can reduce the CPU utilization.
- Checksum Offload
- IP/TCP/UDP checksum is performed to make sure that the packet is correctly transferred
- TCP Segmentation Offload (TSO)
- data > MTU -> divided into MTU sized packets
Bonding Module
bonding driver supports the 802.3 link aggregatioon specification and some original local balancing and fault tolerant implementations.
It achives high level avaialblity and performance improvement.
Security
net.ipv4.tcp_max_syn_backlog = 8192
# Number of times SYN sent for new connection (step 1)
net.ipv4.tcp_syn_retries = 1 新建连接发送SYN次数,默认5,180秒
# Number of times SYNACKs for passive TCP connection. (step 2)
net.ipv4.tcp_synack_retries = 2
# use cookies to process SYN queue overflow
net.ipv4.tcp_syncookies = 1 (0 by default)
# route flush frequency
net.ipv4.route.gc_timeout = 100
# RHEL 7 default: 32768 61000
# outgoing port range
net.ipv4.ip_local_port_range = 2000 65535
# Protect Against TCP Time-Wait
net.ipv4.tcp_rfc1337 = 1
# Decrease the time default value for tcp_fin_timeout connection, FIN-WAIT-2
net.ipv4.tcp_fin_timeout = 15
# Decrease the time default value for connections to keep alive
net.ipv4.tcp_keepalive_time = 300
net.ipv4.tcp_keepalive_probes = 5
net.ipv4.tcp_keepalive_intvl = 15
Disable Source Routing
accept_source_route
- Strict Source Routing (SSR)
- Loose Source Routing (LSR)
sysctl -w net.ipv4.conf.all.accept_source_route=0
Disable multicast packets
sysctl -w net.ipv{4,6}.conf.all.mc_forwarding=0
Disable all ICMP redirected packets
sysctl -w net.ipv{4,6}.conf.all.accept_redirects=0
Inspect Connection States
netstat -tan | awk '{ print $6 }' | sort | uniq -c
This information can be very useful to determine whether you need to tweak some of the timeouts above.
References
TODO: TCP Fast Open
man pages
socket(7)