Language/Encoding
Introduction
In this article we will discuss the merits and demerits of different language/encoding methods.
Table of Contents
Language/Encoding Detection
3 types of detection methods are described below.
A composite approach is recommended in which all 3 types of detection methods are used, to maximize their strengths and complement other detection methods.
- Coding Schema
- most obvious
- iconv -f GB18030 -t UTF-8
- one most often tried first for multi-byte encoding
- could conclude from illegal byte or byte sequence (i.e. unused code point)
- A small set of code points are also specific to a certain encoding
- could run parallel state machine
- 3 states
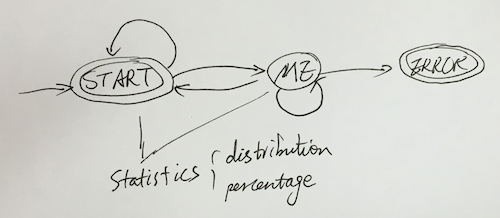
- START state: the state to start with, or a legal byte sequence for character has been identified
- ME state: indicates that the state machine identified a byte sequence that is specific to the charset it is designed for and that there is no other possible encoding which can contain this byte sequence. This will to lead to an immediate positive answer for the detector.
- ERROR state: This indicates the state machine identified an illegal byte sequence for that encoding. This will lead to an immediate negative answer for this encoding. Detector will exclude this encoding from consideration from here on.
- 3 states
- Character Distribution
- 2-Char Sequence Distribution
State Machine